
FROM DATA CATALOGS TO DATA SPACES WITH FIWAREBOX CASSIOPEIA
Everyone says they are building a data space and if you listen long enough you might even start to believe that uploading an Excel file to a portal is now called a federation layer with sovereign data sharing agreements in line with the EU Data Strategy, but in real life we usually start somewhere much more modest, with data catalogs, a bit of metadata, a few connectors, and then slowly discover how big the gap to a real data space actually is.
Everyone says they are building a data space. We did too. For quite a while.
Then we realised that a real FIWARE and GAIA X style data space is far more than a tech stack and configuration checklist and the deeper we dug the clearer it became that we were standing proudly on top of the Dunning-Kruger hill and needed to walk back down, set some realistic milestones and start with an NGSI-LD compliant Context DataHub instead.
At the same time we discovered that most clients are not really ready for a data space anyway because that means deciding who actually owns which data, who is allowed to share it with whom, changing internal processes and responsibilities and habits, and that part cannot be solved with yet another shiny platform no matter how nicely we brand it.
This blog is about that gap and about how we are closing it step by step with FIWAREBox, in particular with our Cassiopeia component, and why building the boring semantic backbone now will save you from very expensive architecture slides later when someone suddenly insists that everything must be called a Data Space.
SHORT RECAP
If I simplify, a classic data catalog tells you what data exists, who owns it, where it is stored, and how you might get access if you are patient enough to click through the metadata pages, which is already a useful starting point, but does not actively move any data and certainly does not understand the meaning of that data.
With our components Extended Metadata Browser (EMB) and Extended Data Browser (EDB) we have already moved beyond this basic idea because they do not just list datasets but help structure them, connect them to business context, and in some cases integrate pipelines and basic governance, so the catalog becomes a living part of your information landscape instead of a static museum of CSV files.
Smart Data Models are the next layer in this story, because they describe entities and relationships in a consistent way, so a building, a parking spot, or an energy meter means the same thing across different systems, and once you adopt them you start to notice how much time you used to lose on explaining to each application what "temperature" or "occupancy" really meant.
In this configuration FIWAREBox is already far more than a passive data catalog, because it hosts running components, context data, connectors, and dashboards that continuously work with live information, yet at the same time it is still honest to admit that this is not a full FIWARE or Gaia-X data space, since we are still missing the federated governance, the contract layer, the identity federation, and all those beautiful policy diagrams that consultants like to draw.
OUR NEXT MILESTONE - AN NGSI-LD COMPLIANT CONTEXT DATAHUB
Before we pretend to have a data space we need a proper semantic backbone and for us that milestone is an NGSI-LD compliant infrastructure, where all relevant data is represented as entities and relationships with JSON-LD, shared vocabularies, and temporal context, so that different parts of the system can talk to each other without constantly reinventing their own data models.
NGSI-LD is essentially a standard way to describe what exists, how it is related, and how it changes over time, and once we agree on that, the rest of the architecture becomes much less about adapters and much more about value.
WHY AUTOMATED PIPELINES COME BEFORE DATA SPACES
It would be beautiful if data always arrived in perfect NGSI-LD JSON-LD format directly into a context broker, but in normal projects it comes from at least four very different directions, such as physical sensors in the field, simulators in test environments, open data portals, and various other data providers ranging from friendly partners to legacy systems that nobody really wants to touch.
All these sources have their own timing and habits, some send new values every second, some only change once per hour or per day, others are static, and some only produce data when a specific event happens, like an alarm, a transaction, or a machine state change, but in all cases we want the result to be the same, namely that new information lands in the context broker as valid JSON-LD, either periodically according to a schedule or instantly as reaction to an event.
This is why we talk about an automatic pipeline as the first concrete step toward a FIWAREBox data space, because without a reliable and repeatable way to ingest, transform, and load data into the Context DataHub, everything else stays in slideware and nothing ever reaches production in a consistent way.
HOW DATA ACTUALLY ENTERS FIWAREBOX
If we look at the realistic path of a data point on its journey into FIWAREBox, it usually starts with a sensor or device that has absolutely no idea what NGSI-LD is and happily speaks its own language, maybe via REST, maybe via a small device API, very often via MQTT or some proprietary protocol that was designed long before anyone in the room had heard of context brokers.
Simulators tend to be a bit more civilized and can sometimes publish directly into a context broker using NGSI-LD, especially when we control both ends of the setup, but even there we often prefer to keep a lightweight connector layer between the simulator and FIWAREBox so that we do not burn NGSI specific logic into the simulation tool itself.
In practice we therefore introduce an IoT connector, which is simply a focused piece of software written in JavaScript, Python, or any other sensible language, that receives data from the device or simulator in whatever native format it uses, normalizes it, and then forwards it to FIWAREBox either via MQTT, HTTP, or directly to the context broker once it is properly mapped.
External data providers behave in a similar way, except that now the "device" is a third party system, so instead of serial lines and field buses we usually have to deal with APIs, webhooks, message brokers, or occasionally direct database access which is technically possible but something we only accept under strict conditions and with a polite note that this should not be the permanent architecture.
Import and export jobs also have their place, especially for historical datasets or initial loads, but they do not give us the event driven behavior we want for a living data backbone, so most of our serious integrations revolve around events, where a new sensor reading, a new record in a system, or a notification from a partner triggers the pipeline that then pushes data through the transformation and into the context broker.
The key idea is that FIWAREBox does not expect the world to suddenly speak NGSI-LD, instead it meets data where it is and uses connectors to gradually teach it better manners.
OPEN DATA AND HARVESTERS - A SLIGHTLY DIFFERENT GAME
When we deal with open data portals such as CKAN, the situation is somewhat different, because these platforms are built around datasets and metadata rather than live event streams, so instead of listening to MQTT topics we typically configure harvesters that periodically visit the portal, read the metadata, and optionally download the associated files or API outputs.
These harvesters give us a structured overview of available datasets, including descriptions, licenses, formats, update frequencies, and access URLs, and they allow us to automatically feed this information into FIWAREBox so that we know not only what open data exists but can also start linking it to our own internal streams and context information.
The important distinction is that open data is usually pulled on a schedule rather than pushed via events, so the pipeline logic for CKAN and similar platforms focuses on periodic harvesting and batch processing instead of real time subscription, even though the final destination is again the same NGSI-LD Context DataHub.
SO NOW WE HAVE DATA SOMEWHERE BUT NOT YET WHERE WE NEED IT
At this point in the story we have succeeded in getting data to exist within our sphere of control, which might mean that it is sitting in an MQTT broker, waiting in CSV or JSON files, appearing in a staging database, or just passing through an internal API that FIWAREBox can call.
This is progress, because at least we are no longer hunting for data across random systems and forgotten export folders, but from the perspective of a FIWARE data space or even just a clean NGSI-LD Context DataHub, the job is still incomplete, since the data is not yet in the correct semantic format and does not follow the Smart Data Models that would allow us to treat it as part of a larger ecosystem.
FROM RAW RECORDS TO JSON-LD AND SMART DATA MODELS
Almost everything that arrives at this stage shares two common properties, it is almost never JSON-LD and it almost never complies with Smart Data Models, which means that before we can proudly call it NGSI-LD context data, we need to perform three important tasks.
First, we have to map the incoming structures to a shared conceptual model, deciding which fields become attributes, which relationships need to be created to other entities, how identifiers are constructed, and how timestamps and spatial information are represented, which is where Smart Data Models give us a ready made vocabulary and save us from designing yet another custom schema.
Second, once we know how the data should look in NGSI-LD, we have to actually push it into the context broker in that format, which means generating valid JSON-LD payloads, attaching the correct @context definitions, handling partial updates or full replacements, and making sure that entities behave as expected from the perspective of downstream applications and analytics.
Third, we must make the entire process automatic, because transformation by hand or via one off scripts may be acceptable for a pilot, but a FIWARE data space or even a serious NGSI-LD Context DataHub requires that the pipeline runs repeatedly, reliably, and transparently, so that new or updated data passes through the same mapping and loading logic without human intervention.
The first two are exactly the problem space where FIWAREBox Cassiopeia lives. The third one is part of Auriga - the pipeline scheduler.
FIWAREBOX CASSIOPEIA NGSI-LD DATA MAPPER AND DATA BRIDGE
Cassiopeia is our answer to the very practical question of how to turn whatever the world gives you into something a FIWARE style platform can actually understand, and you can think of it as the place where all those slightly embarrassing CSV files, home grown JSON APIs, GTFS feeds, GBFS bike sharing streams and other creative formats finally grow up and learn to speak NGSI-LD instead of their own private dialects.
Every city and every larger organisation already has data pouring out of traffic sensors, parking systems, bike sharing docks, air quality monitors, charging stations and back office tools, but this data usually speaks in a dozen different languages, from CSV exported by a vendor that swears it is "standard", through GeoJSON from a mapping product, all the way to transit feeds and proprietary JSON that only one team really understands, so Cassiopeia steps in as the universal translator and data bridge that smart cities and utilities have been quietly waiting for.
In simple terms Cassiopeia is a high performance data transformation engine that takes these heterogeneous inputs and turns them into NGSI-LD entities aligned with FIWARE Smart Data Models, so instead of fifteen incompatible views of reality you get one consistent context graph that your applications, dashboards and analytics can actually reuse, and from a decision maker perspective that means you stop paying for the same integration work again and again every time a new system arrives.
It has a Data Model Selection, Identity Configuration, Attribute mapping, and Save Configuration.
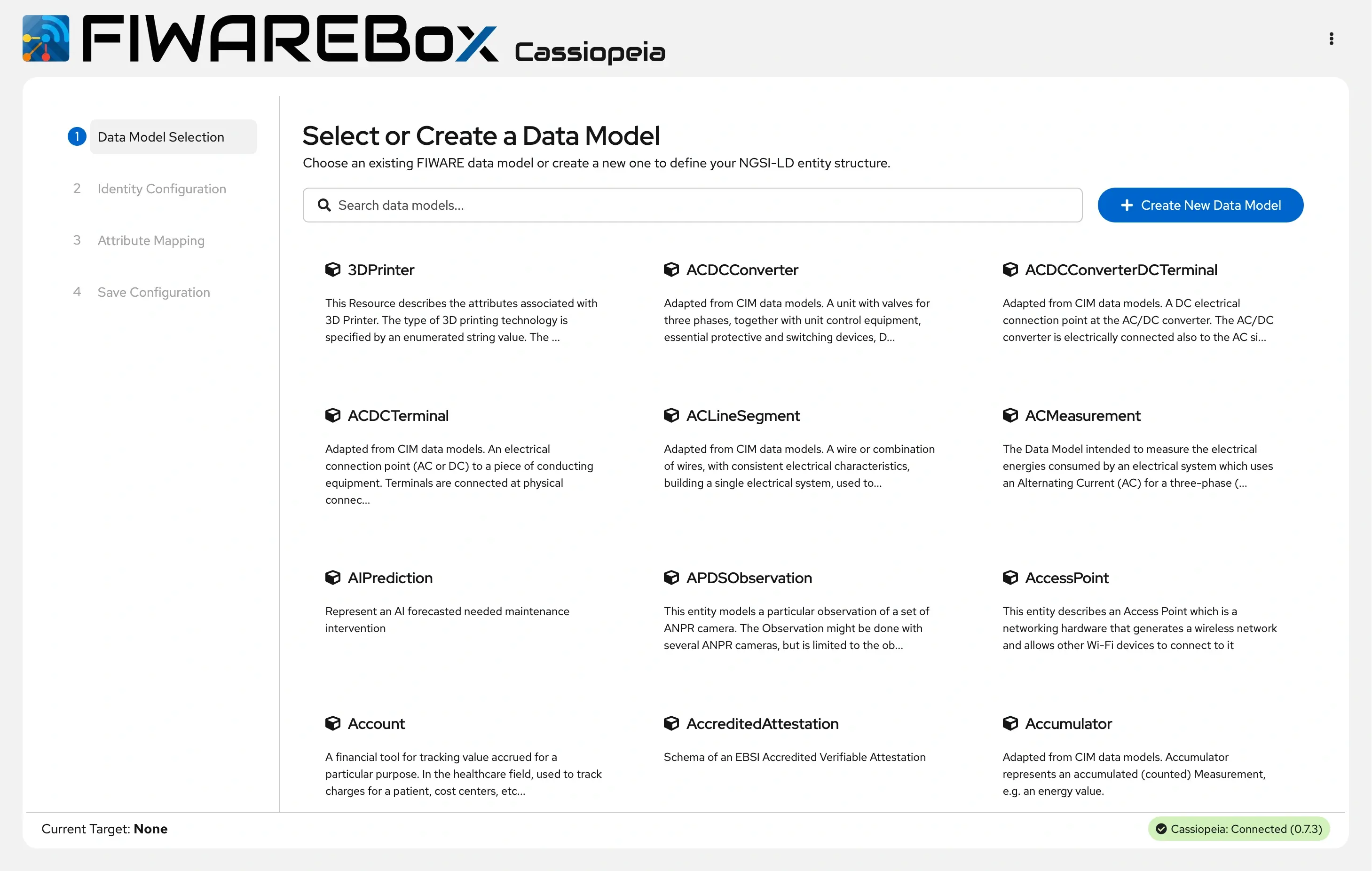
FIWAREBox Cassiopeia - Data Model Selection
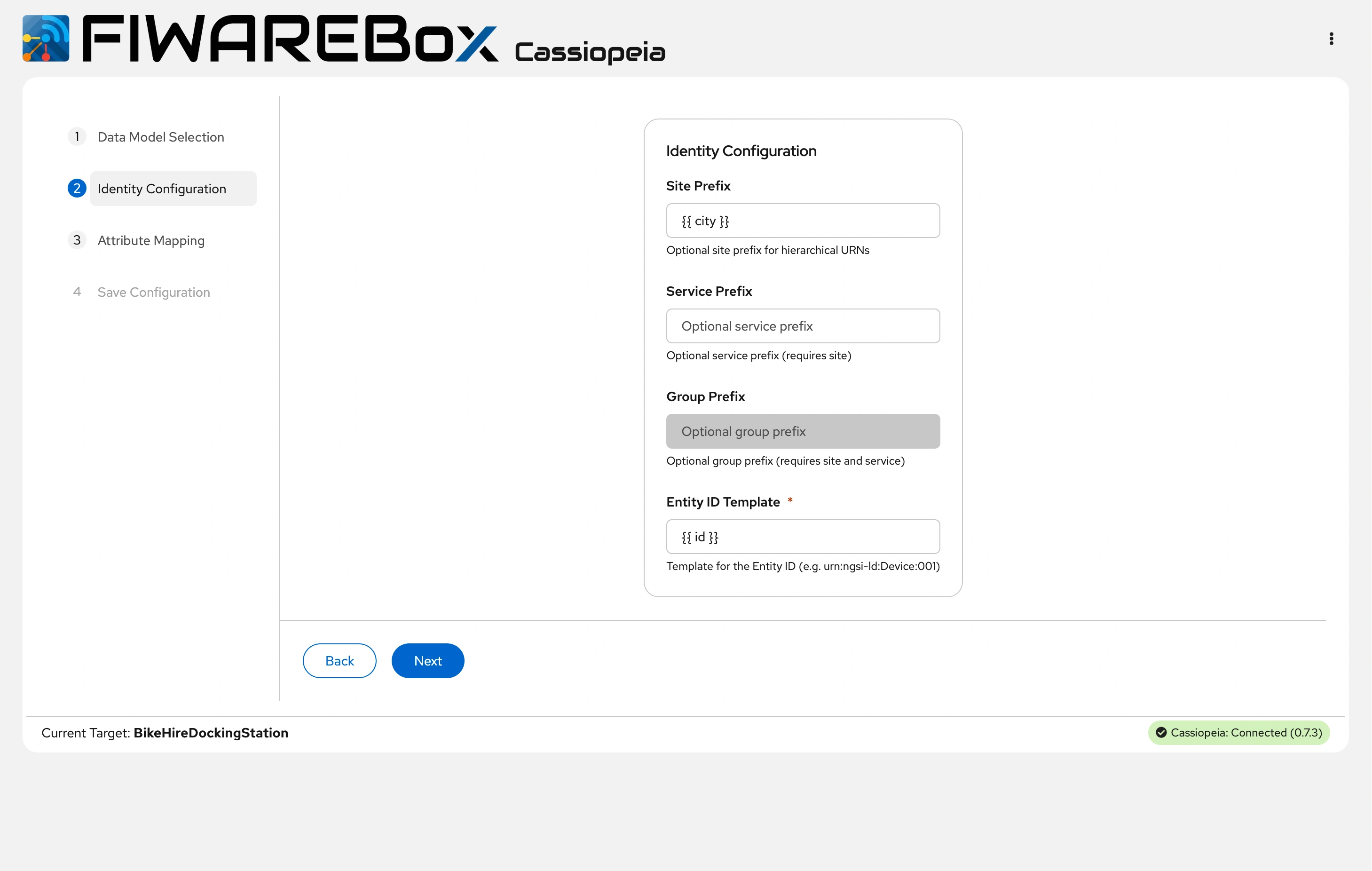
FIWAREBox Cassiopeia - Identity Configuration
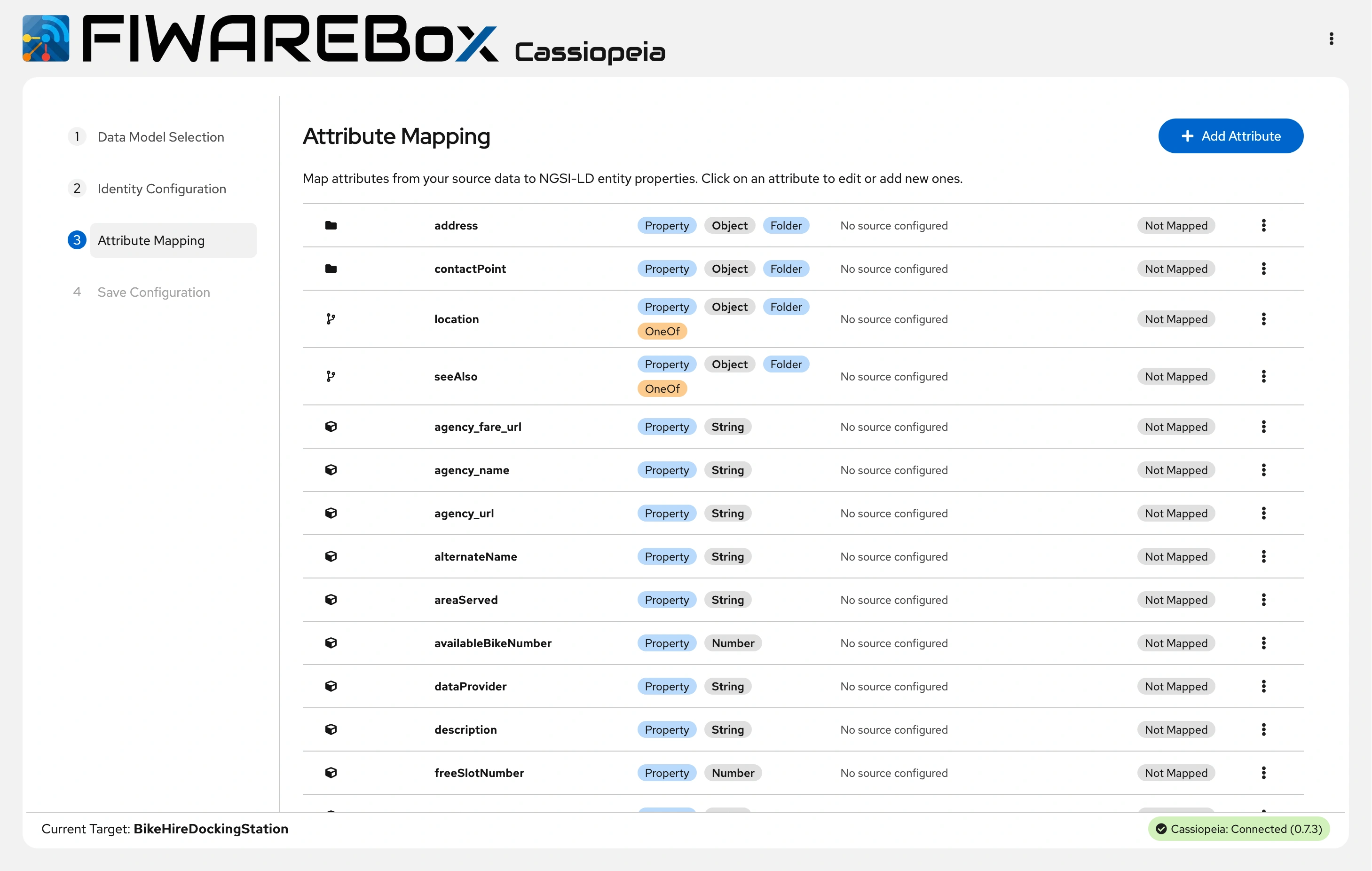
FIWAREBox Cassiopeia - Attribute Mapping
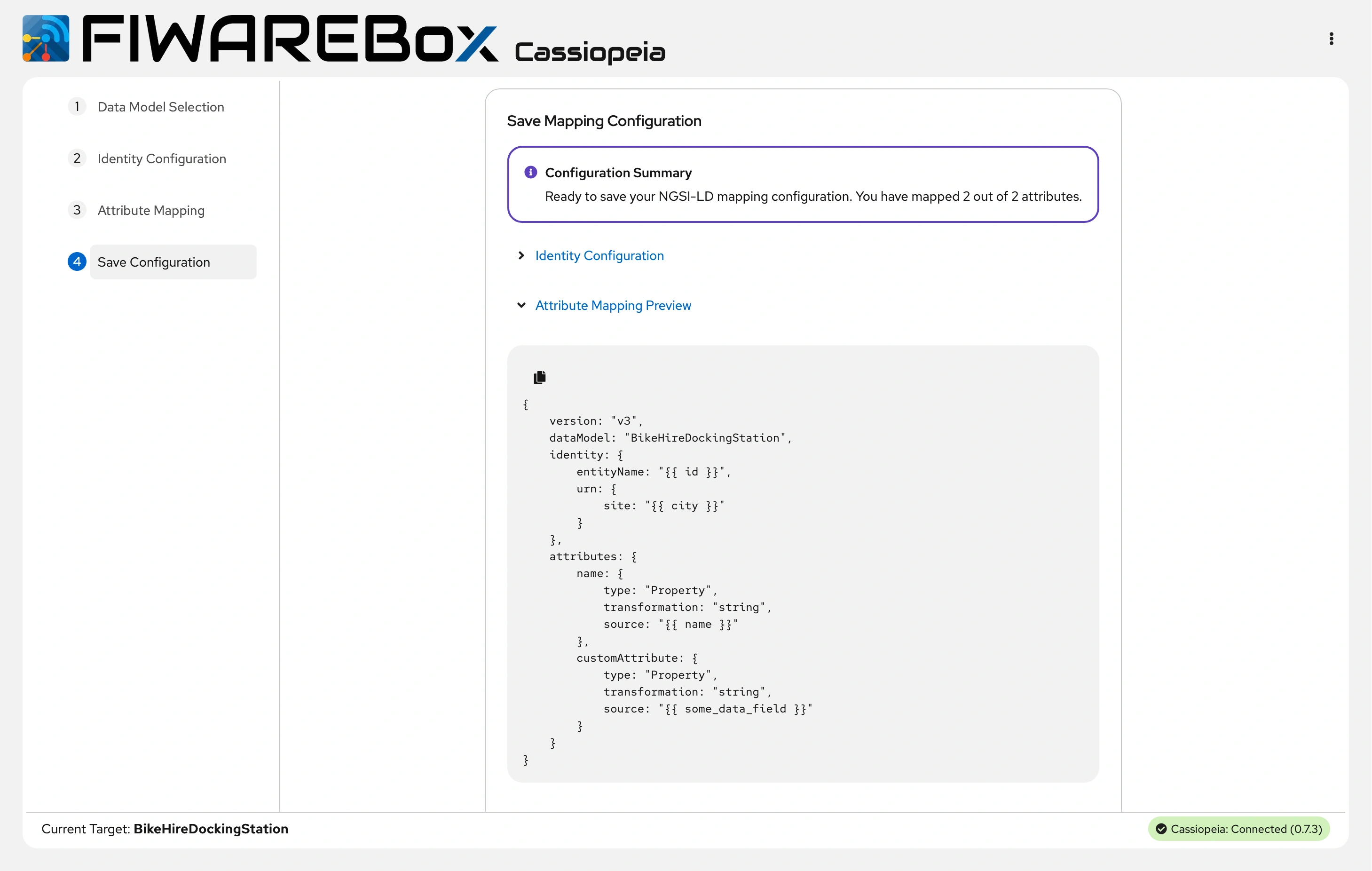
FIWAREBox Cassiopeia - Save Configuration
Architecturally Cassiopeia is built around a single unified pipeline with pluggable ingestors, which means that CSV, JSON, GeoJSON, GTFS, GBFS, MsgPack and future formats each have their own specialised entry module, but once the data is in the system it flows through the same processing stages, so adding a new format does not require you to redesign the whole engine or start a new side project.
Under the hood Cassiopeia uses mapping templates that describe how an incoming dataset should be split into entities, which attributes should be created, how relationships are built, and where conditional logic or synthetic entities are needed, for example when one row of a CSV file must produce several linked entities or when a transport feed like GTFS needs to be converted into stops, routes, trips, and calendars in a way that makes sense in an NGSI-LD world.
Because GTFS and GBFS are so common in mobility use cases, Cassiopeia comes with pre built configurations for these formats, which means that you do not start from a blank sheet every time a city decides it would like to reuse its existing open transport feeds inside a FIWARE based platform, and the same principle applies as we add more templates for recurring patterns.
The pipeline itself is organised into several logical stages such as ingest, expand, resolve, extract, transform, validate and write, and these stages can run in parallel and in multiple instances, which gives us the kind of throughput you need when an entire city decides to publish real time mobility or environmental data and still expects the platform to feel responsive rather than academic.
The real intelligence of Cassiopeia lives in its mapping layer, where we use a template driven approach based on a powerful engine that allows conditional logic, value transformations and complex derivations without writing custom code for each source, so your team describes how fields, attributes and relationships should look and Cassiopeia does the repetitive work of turning individual records into well formed NGSI-LD entities.
Because real world data is rarely flat, Cassiopeia is designed to handle complex relationship modelling and synthetic entity generation, so if your source feed does not explicitly describe operators, organisations or related assets, the engine can create these entities on the fly and maintain consistent references between them, which is exactly what you need when you want to navigate your data as a graph instead of a pile of tables.
Before anything leaves the pipeline it is validated against Smart Data Models, so entities that reach your NGSI-LD context broker or your file outputs are already checked for structural and semantic consistency, which saves a lot of painful debugging later when some application fails because someone silently changed a schema on the input side.
From an engineering point of view Cassiopeia is implemented with performance and reliability in mind, using a technology stack that gives us high throughput and a modest resource footprint, which is a polite way of saying that it can handle serious workloads without demanding its own personal data center, and its modular design means new formats and mappings can be introduced without disturbing existing pipelines.
For operations we keep the deployment model flexible, so the same configuration can either write directly into any NGSI-LD compliant context broker for near real time use cases or produce files for batch processing where that makes more sense, and in both cases you configure the mapping once and let Auriga, our scheduler and orchestrator, decide when and how often the transformations should run.
Why does this matter at city or enterprise level, beyond the technical elegance? For cities it means that parking, traffic, public transport, micro mobility and environmental data can finally be brought into one coherent picture instead of living in isolated silos that never talk to each other; for integrators it means that onboarding a new dataset becomes a matter of hours spent on a mapping configuration instead of weeks spent building yet another tactical ETL; and for the wider FIWARE ecosystem it means that bringing new organisations into an NGSI-LD world is no longer blocked by the format of their legacy systems. Similar for Industry or any IoT vertical.
From the outside Cassiopeia may not look spectacular, but it quietly solves the painful middle part of every data project, which is the moment where you realize that all your inputs are slightly different and all your outputs are expected to be beautifully standardized, and without something like Cassiopeia this is usually the point where timelines slip and budgets start to grow.
Put differently, if you cannot integrate your data you cannot transform your services, and Cassiopeia is the component in FIWAREBox that quietly carries you from fragmented data chaos toward unified smart city and industrial intelligence, without vendor lock in, without heroic amounts of custom plumbing and without pretending that every project needs to reinvent the same data bridge from scratch.
WHAT HAPPENS AFTER CASSIOPEIA
Once Cassiopeia has finished turning raw inputs into clean NGSI-LD entities, we still need someone to tell it when to work, where to take data from and how to leave traces, otherwise it would be a very elegant engine that only runs when someone remembers to press a button.
This is where Auriga – our pipeline scheduler and orchestrator – will step in with time based jobs, event based triggers and proper logging so that every run knows what it processed, which mapping it used and what it wrote into the context broker, and so that debugging does not require a crime scene investigation team.
The details of Auriga, triggers, monitoring and how we turn this into a full end to end pipeline deserve their own blog post, so for now you can simply remember that Cassiopeia cleans and reshapes the data and Auriga will soon be the slightly bossy conductor that keeps the whole show running.
WHAT IS IN IT FOR DECISION MAKERS
From a decision maker point of view all this talk about JSON LD, Smart Data Models, and mapping templates only matters if it translates into concrete benefits, and in this case the benefits are very pragmatic.
First, you obtain an NGSI-LD compliant Context DataHub that does not depend on a single vendor format or proprietary schema, which makes future integration projects easier and gives you room to change suppliers or technologies without rewriting every interface, which is an important property if you are aiming at something that deserves to be called a FIWARE data space in the long run.
Second, you reduce the cost and risk of onboarding new data sources, because instead of starting from scratch each time, you plug them into the existing pipeline, configure the necessary mappings in Cassiopeia, and let the scheduler handle the rest, which means that pilots can move faster and successful experiments can evolve into production without a complete redesign.
Third, you create a foundation where sharing data across departments, companies, or even cities becomes a realistic discussion rather than a slide, since the data is already structured according to shared Smart Data Models and exposed through a context broker that follows NGSI-LD, which is exactly the type of environment that FIWARE data spaces are supposed to inhabit.
In other words, FIWAREBox with Cassiopeia and an NGSI-LD Context DataHub does not magically turn your organization into a data space overnight, but it gives you a concrete, working platform where the technical prerequisites are in place, so that when people start talking about governance, contracts, and federated policies, you are not secretly wondering whether the data pipeline will even survive a second pilot.
And if you are curious how this looks in your specific context, whether that is a city, a utility, or an industrial site, then the next logical step is not another strategy workshop but a small, focused pilot where we connect a few real data sources, run them through Cassiopeia, and show on real dashboards how this translates into better decisions and a cleaner path toward FIWARE data spaces.
CONCLUSION
From a tech point of view, if CKAN alone is 0 and a fully fledged FIWARE and GAIA X style data space with federation, governance, contracts and marketplace is 100, then with EMB or EDB, Cassiopeia – NGSI-LD mapper, Auriga – pipeline scheduler and orchestrator, Libra - PEP proxy and access control, Lynx - linked data extender, plus the NGSI-LD broker and temporary storage, we are probably somewhere around 60 percent of the way there.
For what our clients actually need today, given that most of them are still busy just figuring out ownership, responsibility and basic data governance, we can realistically cover something like 85 to 90 percent of their real needs.
This is a polite way of saying that our tech is already slightly ahead of their organisation and that is still a very comfortable place to be.
In my slightly modified Pareto principle for this case, it simply means that with roughly 60 percent of the data space stack we already solve well over 80 percent of the problems that really hurt them today.
FUTURE STEPS
Now that Cassiopeia is in place as our NGSI-LD mapper and data bridge, the next logical step is to give it a slightly bossy colleague called Auriga – the scheduler and orchestrator – who will decide when each pipeline runs, which source it pulls from, how often it refreshes, and how loudly it complains when something goes wrong.
Auriga will bring time based jobs, event based triggers and proper logging into the picture, so instead of manual runs and polite hope, we will have repeatable schedules that react to MQTT events, file arrivals or IoT agent updates, while leaving behind enough traces for monitoring and debugging without turning every incident into a forensic exercise.
After that we can finally start playing with richer pipeline visibility and simple operational dashboards that show which data flows are healthy, which ones are delayed and which ones are misbehaving, and only then does it really make sense to go back to the data space story and talk about governance, contracts and all the non technical fun that comes with FIWARE and GAIA X style ecosystems.
Just like with EMB and EDB, Cassiopeia follows the same rule under FIWAREBox:
INVEST 20%, GAIN 80%.
Invest roughly 20 percent of the full data space stack and solve well over 80 percent of the real problems, by focusing first on getting data into NGSI-LD and only then on the higher level buzzwords.
Instead of inventing yet another generic ETL framework, we built a focused NGSI-LD mapper and are adding an equally focused scheduler, which gives cities and companies something immediately usable on top of their existing systems, without forcing them into a full blown data space programme before they are organisationally ready.
Sometimes the biggest step towards a data space is not a grand new architecture, but a very down to earth improvement to the way data is mapped, scheduled and monitored.
DISAGREE, COMMENT, OR WISH TO KNOW MORE?
